Prometheus高基数问题
什么是高基数
要理解高基数,我们先要知道什么是基数 (Cardinality)
- 基数 (Cardinality):一个数据集中某个字段(列)的唯一值的数量
知道了基数是什么,那么高基数就好理解了,主要多了一个高嘛
- 高基数 (High Cardinality):指一个字段中包含极其多的唯一值。
这么看描述的太学术,不够通俗易懂,我们来距离说明
举例
| 字段(列) | 例子 | 唯一值数量 | 基数类型 |
|---|---|---|---|
| 性别 | "男", "女", "其他" | 3 | 低基数 |
| 国家 | "中国", "美国", "日本", ... | ~200 | 低基数 |
| 城市 | "北京", "上海", "纽约", ... | 成百上千 | 中等基数 |
| 用户ID | uuid-1, uuid-2, uuid-3, ... | 百万、千万、上亿 | 高基数 |
| 电子邮箱 | a@test.com, b@test.com, ... | 百万、千万、上亿 | 高基数 |
| 请求ID (Trace ID) | trace-xyz..., trace-abc... | 几乎每个都是唯一的 | 极高基数 |
| IP地址 | 192.168.1.1, 10.0.0.5, ... | 可能是千万级 | 高基数 |
| 精确时间戳 (纳秒) | 1678886400123456789 几乎每个都是唯一的 | 极高基数 |
结合网上的图片来看可能更清晰
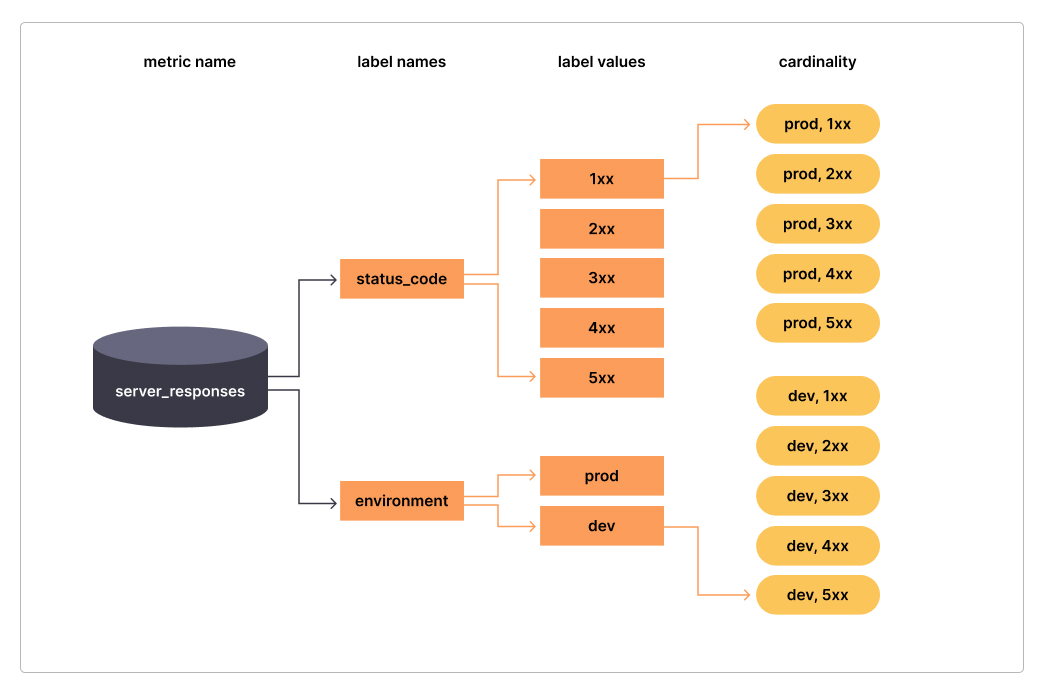
- 标签
status_code的基数是5,(1xx、2xx、3xx、4xx、5xx),-environment的基数是2(prod、dev) server_responses的总体基数是10。
为什么会出现高基数
高基数问题主要出现在监控领域
最典型的例子是在 Prometheus 这样的时序数据库 (TSDB) 中:
- 时序数据库的原理:
Prometheus中,每一组唯一的标签(Label)组合都会创建一条全新的时间序列(Time Series)。
我们在进行埋点上报的时候,比如要上报 http_requests_total(HTTP 请求总数)
正确设计(低基数):http_requests_total{method="GET", path="/api/users", status="200"}。method、path、status 的组合是有限的(可能几千种)
实际这个基数数量也不算小,如果我们由于资源有限,可以更灵活的设计,比如不区分
method,因为我们监控主要看请求的趋势,而不是为了数据分析,不需要这么精准,更精准的数据分析需要单独进行数据分析,而不是在监控告警这里分析
错误(高基数):http_requests_total{method="GET", path="/api/users", user_id="uuid-abc-123..."}
如果我们把 user_id(假如有1000 万个用户)或 trace_id(每次请求都唯一)放进了标签里,我们就会瞬间制造出1000 万条甚至上亿条时间序列。
这被称为基数爆炸(Cardinality Explosion)
它会迅速耗尽监控系统的内存,导致其崩溃
所以像一些云监控比如Datadog 的标准套餐(例如按主机付费)可能每台主机只“免费”包含 100 或 500 条自定义指标。当你因为一个高基数标签导致指标数量从 6 飙升到 600 万时,你超出的那几百万条指标将按条、按小时支付极其高昂的超额费用
高基数的危害
Prometheus 是一个基于拉取的、维度化的时序数据库,其核心数据模型是:
<metric_name>{<label1>=<value1>, <label2>=<value2>, ...}
高基数会带来以下严重问题:
-
内存消耗爆炸式增长:Prometheus 会将所有活跃的时间序列数据缓存在内存中以便快速查询。高基数会创建海量时间序列,导致内存使用量(RAM)急剧上升,直至 OOM(Out Of Memory)崩溃。
-
磁盘写入负载高:海量的时间序列数据需要被持久化到磁盘,会给 SSD/HDD 带来巨大的写入压力。
-
查询性能急剧下降:当你执行一个 PromQL 查询时,引擎需要从海量序列中扫描和聚合数据,这会变得非常缓慢,甚至超时。
-
WAL(预写日志)膨胀:为了保证数据不丢失,Prometheus 会先将数据写入 WAL。高基数会导致 WAL 文件巨大,写入缓慢。
简单来说,高基数会从内存、磁盘、CPU 和网络 I/O 等多个维度压垮 Prometheus
如何解决和避免高基数问题
预防大于治疗
最好的方式就是从源头规避,预防大于治疗
在Metrics上报的时候我们定义一系列的标准
-
严禁高基数标签:绝对不要将 UUID、用户ID、邮箱、Trace ID、IP 地址等放入 Prometheus 标签。
-
使用“桶” (Bucketing):
- 不要:
status="200", status="201", status="400", status="404", status="500", status="503"
- 不要:
-
规范化和聚合:
- 不要:
path="/api/user/123/profile", path="/api/user/456/profile" - 要:
path="/api/user/{user_id}/profile"(在代码中对 URL 进行规范化)
- 不要:
-
将高基数数据移至日志/追踪: 如果你想看“某个特定用户 user-123 的请求失败率”,你不应该在指标里查。
正确做法: 通过指标(低基数)发现“5xx 错误率激增”。 跳转到日志(如 Loki, Elasticsearch)或追踪(如 Jaeger, Tempo)系统。 在日志/追踪系统中查询高基数的
user_id或trace_id来定位具体问题
这些主要是从使用上进行优化,如果要进行性能优化,只能另寻他法
使用专门的数据库
-
列式数据库 (Columnar Databases):
-
代表:ClickHouse, Google BigQuery, Snowflake。
-
为什么有效:传统数据库(行式)在查询时必须读取整行数据。而列式数据库只读取你查询所需的列。
-
场景:你要在 10 亿行日志中查询 GROUP BY ip_address。
-
行式数据库 (MySQL):读取 10 亿行 所有数据(timestamp, ip,
user_id, url, body...),然后丢弃大部分,只留下 ip 列进行计算。非常慢。 -
列式数据库 (ClickHouse):只读取 ip_address 这一列的数据。I/O 降低了 90% 以上,并且由于同列数据高度相似,压缩率极高,查询速度快上百倍。
-
-
-
现代时序数据库 (TSDB):
-
代表:TimescaleDB。
-
为什么有效:像 InfluxDB 这样的传统 TSDB 在高基数下索引会膨胀。而 TimescaleDB(基于 PostgreSQL)利用其**时空分区(Time-Space Partitioning)**特性。
-
它不仅按时间(如每天)自动分区,还可以按高基数字段(如 device_id)进行空间分区。这意味着索引被分解成成百上千个小索引,查询时只需加载相关的小索引,从而在高基数下保持高性能。
-
使用近似算法(Approximate Algorithms)
-
问题:
SELECT COUNT(DISTINCT user_id) FROM logs;(计算日活跃用户)。这是一个在传统数据库上极其缓慢的操作,因为它需要将所有user_id加载到内存中去重。 -
解决方案:HyperLogLog (HLL) 算法。
-
它是什么:一种概率算法,可以用极小的内存(几 KB)来估算一个巨大集合的基数(去重数)。
-
为什么有效:它牺牲了 100% 的准确性(例如,换来 99% 的准确率),但将查询速度提升了成千上万倍,内存消耗降低了几个数量级。对于“网站日活是 1000 万还是 1001 万”这样的问题,一个高精度的估算值完全够用。
-
应用:Redis、ClickHouse、BigQuery 等都内置了 HLL 功能(通常函数名为 APPROX_COUNT_DISTINCT 或 HLL)。
总结
解决 Prometheus 高基数问题的思路可以概括为:
| 阶段 | 核心行动 | 具体方法 |
|---|---|---|
| 预防 | 审慎设计 | 标签用于维度,而非实体。避免使用 user_id, ip 等。 |
| 诊断 | 快速定位 | 使用 topk(10, count by ...) 和 TSDB Status 页面找到问题指标和标签。 |
| 治理 | 削减基数 | 1. 代码层面:移除或替换高基数标签。2. Relabeling:抓取时删除标签或丢弃指标。3. Recording Rules:预聚合,化详细数据为统计值。 |
| 架构 | 升级方案 | 1. 迁移到 VictoriaMetrics。2. 采用 Thanos/Cortex 进行降采样。 |
本文为博主原创文章,未经博主允许不得转载